
Workshop at 21.-22.03.2024 in Potsdam
Confirmed invited speakers include
Gilles Blanchard (Paris, France)
Merle Behr (Regensburg, Germany)
Elisabeth Gassiat (Paris, France)
Sonja Greven (Berlin, Germany)
Claudia Kirch (Magdeburg, Germany)
Michael Kohler (Darmstadt, Germany)
Enno Mammen (Heidelberg, Germany)
Thomas Mikosch (Copenhagen, Denmark)
Eric Moulines (Paris, France)
Jonas Peters (Zürich, Switzerland)
Venue
Campus Neues Palais of the University Potsdam
Am Neuen Palais 10, 14469 Potsdam, Germany
Building 9, rooms 1.14 and 1.15 on the first floor
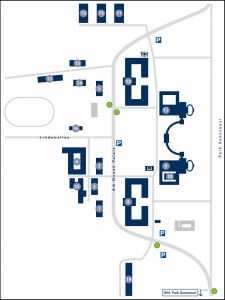
- The closest bus stations are Neues Palais, or Camp. Universität/Lindenallee
Potsdam. Both are less than 5min walking distance from the workshop venue. - The closest train station is Park Sanssouci. It is 10 a min walking distance from the
workshop venue. Alternatively one can use the bus station Park Sanssouci below the
train platforms, it is 6min by bus 605, 697 or X5 to the station Neues Palais or
Camp. Universität/Lindenallee Potsdam (some bus don’t stop at both), it is then
5min walking distance. - If you come by plane, note that there is a direct train from the airport BER to the train
station Park Sanssouci: the RB22. But it is quite irregular (less than once per hour).
Please check the DB website for precise time schedules and itineraries.
The coffee breaks will be served upstairs (second floor) of the room for the talks (building 9,
room 2.04), and the lunches will be taken at the Mensa, which is the restaurant of the
university (in building 12). There will also be coffee served in the coffee break room after
lunch except on Friday.
The workshop finishes on Friday 22nd of March 2024 at 12:30 (or after lunch at the cafeteria).
There will be someone in the coffee break room (room 2.04) until 14:00 on Friday in case
you want to leave your luggage there.
Program
Thursday, March 21, 2024
- 08:30 – 09:00 Welcome coffee and opening remarks
-
09:00 – 09:50 Jonas Peters (ETH Zürich, Switzerland)
Can we go beyond the observed distribution? Estimating price elasticities and testing hypotheses under distributional shifts
When aiming to predict how an observed system reacts to an active change, that is, an intervention, applying classical prediction methods does not suffice. Instead, we need to use causal inference techniques that usually come with strong assumptions. In this talk, we present some ideas about estimating price elasticity in electricity markets. We also discuss a theoretical question that occurs at several places when considering changes in the distribution: can we test hypotheses about the shifted distribution even though we do not observe data from it?
-
10:00 – 10:50 Sonja Greven (Humboldt University of Berlin, Germany)
Elastic methods for curves in two or more dimensions
We propose statistical methods for curve-valued responses in two or more dimensions, where only the image but not the parametrization of the curves is of interest. Examples of such data are handwritten letters, movement paths or outlines of objects. In the square-root-velocity framework, a parametrization invariant ‘elastic’ distance for curves is obtained as the quotient space metric with respect to the action of re-parametrization (‚warping’), which is by isometries. We first provide methods and algorithms to approximate the elastic distance for such curves even if sparsely sampled, propose to use spline curves for modelling Fréchet means and show identifiability of the spline model modulo warping. We then discuss the generalization of ‚linear‘ regression to quotient metric spaces more generally, before illustrating the usefulness of our approach for the special case of curves modulo re-parametrization. We apply our methods to the classification of Parkinson’s patients and controls based on a spiral drawing test, to clustering and averaging GPS tracks with different speeds, and to disentangling the different effects of Alzheimer’s disease and normal ageing on the shape of the human hippocampus via elastic regression. All developed methods are implemented in the R-package elasdics.
(joint work with Lisa Steyer and Almond Stöcker) - 11:00 – 11:30 Coffee break
-
11:30 – 12:20 Claudia Kirch (Otto von Guericke University Magdeburg, Germany)
Scan statistics for the detection of anomalies in large image data
Anomaly detection in random fields is an important problem in many applications including the detection of cancerous cells in medicine, obstacles in autonomous driving and cracks in the construction material of buildings. Scan statistics have the potential to detect local structure in such data sets by enhancing relevant features. Frequently, such anomalies are visible as areas with different expected values compared to the background noise where the geometric properties of these areas may depend on the type of anomaly. Such geometric properties can be taken into account by combinations and contrasts of sample means over differently-shaped local windows. For example, in 2D image data of concrete both cracks, which we aim to detect, as well as integral parts of the material (such as air bubbles or gravel) constitute areas with different expected values in the image. Nevertheless, due to their different geometric properties we can define scan statistics that enhance cracks and at the same time discard the integral parts of the given concrete. Cracks can then be detected using a suitable threshold for appropriate scan statistics.
In order to derive such thresholds, we prove weak convergence of the scan statistics towards a functional of a Gaussian process under the null hypothesis of no anomalies.
The result allows for arbitrary (but fixed) dimension, makes relatively weak assumptions on the underlying noise, the shape of the local windows and the combination of finitely-many of such windows. These theoretical findings are accompanied by some simulations as well as applications to semi-artifical 2D-images of concrete.
This is joint work with Philipp Klein (Otto-von-Guericke University Magdeburg) and Marco Meyer (University of Hannover). - 12:20 – 14:30 Lunch break
-
14:30 – 15:20 Gilles Blanchard (Université Paris Saclay, France)
Estimating multiple high-dimensional vector means by aggregation
We aim at estimating a possibly large number of high-dimensional means for different probability distributions on a common space, when independent samples are available from each distribution. This problem is relevant for instance for the goal of estimating, for multiple distributions, their kernel mean embeddings (KME) — a very popular tool in recent years in machine learning.
We consider convex combinations of empirical means of each sample to form estimators, by an aggregation scheme that minimizes over possible weight vectors an upper confidence bound on the quadratic risk.
We analyze the improvement in quadratic risk of this scheme over the simple empirical means. We allow full heterogeneity of sample sizes and of distribution covariances, and zero a priori knowledge of the structure of the mean vectors, nor of the covariances. A particular feature of our analysis is the focus on the role of the effective dimension of the data in a „dimensional asymptotics“ point of view, highlighting that the risk improvement of the proposed method satisfies an oracle inequality approaching an adaptive (minimax) improvement as the effective dimension grows large.
(This is joint work with Jean-Baptiste Fermanian and Hannah Marienwald) - 15:30 – 16:00 Coffee break
-
16:00 – 16:50 Eric Moulines (Institut Polytechnique de Paris, France)
Bayesian inverse problems with score-based diffusion priors.
Since their first introduction, score-based diffusion models (SDMs) have been successfully used to solve a variety of linear inverse problems in finite-dimensional vector spaces, as they provide an efficient approximation to the prior distribution. Score-based diffusion models allow an efficient simulation of the a priori law, but do not provide a simple density expression: most classical methods – variational or MCMC approaches – are therefore not applicable. Recently, a number of solutions have been proposed, which we will present and evaluate. We will also show that many current methods are not able to capture the a posteriori distribution. We will also present two new methods we have recently developed that provide theoretical guarantees. We will illustrate these methods using different benchmarks.
-
17:00 – 17:50 Michael Kohler (TU Darmstadt, Germany)
On the rate of convergence of an over-parametrized Transformer classifier learned by gradient descent
Classification from independent and identically
distributed random variables is considered.
Classifiers based on over-parametrized
transformer encoders are defined where
all the weights are learned by gradient descent. Under suitable
conditions on the a posteriori probability an upper bound on the
rate of convergence of the difference of the misclassification
probability of the estimate and the optimal misclassification probability
is derived. - 19:00 Dinner
- 08:30 – 09:00 Welcome coffee
-
09:00 – 09:50 Merle Behr (University of Regensburg, Germany)
Provable Boolean interaction recovery from tree ensemble obtained via random forests
Random Forests (RFs) are at the cutting edge of supervised machine learning in terms of prediction performance, especially in genomics. Iterative RFs (iRFs) use a tree ensemble from iteratively modified RFs to obtain predictive and stable nonlinear or Boolean interactions of features. They have shown great promise for Boolean biological interaction discovery that is central to advancing functional genomics and precision medicine. However, theoretical studies into how tree-based methods discover Boolean feature interactions are missing. Inspired by the thresholding behavior in many biological processes, we first introduce a discontinuous nonlinear regression model, called the “Locally Spiky Sparse” (LSS) model. Specifically, the LSS model assumes that the regression function is a linear combination of piecewise constant Boolean interaction terms. Given an RF tree ensemble, we define a quantity called “Depth-Weighted Prevalence” (DWP) for a set of signed features S. Intuitively speaking, DWP(S) measures how frequently features in S appear together in an RF tree ensemble. We prove that, with high probability, DWP(S) attains a universal upper bound that does not involve any model coefficients, if and only if S corresponds to a union of Boolean interactions under the LSS model. Consequentially, we show that a theoretically tractable version of the iRF procedure, called LSSFind, yields consistent interaction discovery under the LSS model as the sample size goes to infinity. Finally, simulation results show that LSSFind recovers the interactions under the LSS model, even when some assumptions are violated.
Reference: https://www.pnas.org/doi/10.1073/pnas.2118636119
Co-authors: Yu Wang, Xiao Li, and Bin Yu (UC Berkeley) -
10:00 – 10:50 Elisabeth Gassiat (Université Paris Saclay, France)
Model-based Clustering using Non-parametric Hidden Markov Models
Thanks to their dependency structure, non-parametric Hidden Markov Models (HMMs) are able to handle model-based clustering without specifying group distributions. The aim of this work is to study the Bayes risk of clustering when using HMMs and to propose associated clustering procedures. We first give a result linking the Bayes risk of classification and the Bayes risk of clustering, which we use to identify the key quantity determining the difficulty of the clustering task. We also give a proof of this result in the i.i.d. framework, which might be of independent interest. Then we study the excess risk of the plugin classifier. All these results are shown to remain valid in the online setting where observations are clustered sequentially. Simulations illustrate our findings.
- 11:00 – 11:30 Coffee break
-
11:30 – 12:20 Thomas Mikosch (University of Copenhagen, Denmark)
Extreme value theory for heavy-tailed time series
We will consider regularly varying time series. The name comes from the marginal tails which are of power-law type. Davis and Hsing (1995) and Basrak and Segers (2009) started the analysis of such sequences. They found an accompanying sequence (spectral tail process) which contains the information about the influence of extreme values on the future behavior of the time series, in particular on extremal clusters. Using the spectral tail process, it is possible to derive limit theory for maxima, sums, point processes… of regularly varying sequences, but also refined results like precise large deviation probabilities for these structures.
In this talk we will give a short introduction to regularly varying sequences and and explain how the aforementioned limit results can be derived. - 12:30 Lunch break
Hotels
Hotel MAXX Hotel Sanssouci Potsdam
We booked the hotel:
MAXX Hotel Sanssouci Potsdam (Address: Allee nach Sanssouci 1 14471 Potsdam)
for you, according to the dates that you gave us. Check in is after 3pm on the day of arrival and until noon on the day of departure.
The easiest way to go to the workshop venue from the hotel is by bus, and the whole trip is
ca 20mn: take the bus 605 at the bus station Luisenplatz-Süd/Park Sanssouci (5mn walk
from the hotel) and get off the bus at the station Camp. Universität/Lindenallee Potsdam,
or Neues Palais – you are then just 5mn away from the workshop venue.
Please check the DB website for precise time schedules and itineraries.
We booked the hotel:
Holiday Inn Express & Suites Potsdam (Address: Am Kanal 15, Potsdam, DE 14467)
for you, according to the dates that you gave us. Check in is after 3pm on the day of arrival and until noon on the day of departure.
The easiest way to go to the workshop venue from the hotel is by bus, and the whole trip is
ca 20mn: take the bus X5, 605 or X15 at the bus station Platz der Einheit/West (5mn walk
from the hotel) and get off the bus at the station Camp. Universität/Lindenallee Potsdam,
or Neues Palais – you are then just 5mn away from the workshop venue.
Please check the DB website for precise time schedules and itineraries.
Get-together on Wednesday 20.03
We are pleased to invite you for a small get-together on the 20.03.2024 between 18:00 and
19:30 at the conference venue (Campus Neues Palais, Haus 9, room 2.06). There will be
some light snacks and refreshments.
Restaurant for the dinner on Thursday 21.03
We are pleased to invite you for dinner on the 21.03.2024 at 19:00 at the restaurant:
Tamada Sellostraße 19, 14471 Potsdam
The easiest way to go to the restaurant from the workshop venue is by bus and the trip
takes ca 15mn: take the bus 605 from the bus station Neues Palais and get off at Auf dem
Kiewitt – you are then just 5mn away from the restaurant.
The hotel Holiday Inn Express & Suites Potsdam is then 25mn away by foot from the
restaurant, or can be reached by various bus or trams in ca 15mn (e.g. take the bus 605 at
Auf dem Kiewitt and get off at Platz der Einheit/West).
Please check the DB website for precise time schedules and itineraries.
Download the Info-PDF: here
The workshop is sponsored by the DFG Research Unit 5381